Apache SPARK ile Öneri Sistemleri – Spark Recommendation System – Bölüm 2
Bir önceki çalışmamızda ALS metodunu kullanarak verimizden tahminleri elde edebilmek adına veri setlerimizi eğittik. Burada ki çalışmalarımızda açık derecelendirmeye sahip olan veri setimizin üzerinde çalışmaya devam edeceğiz. Evet bu noktaya kadar ALS algoritması ile tahminlemeler yaptık ve yüksek doğruluk değerlerine sahip olmuştuk. Fakat buraya kadar yaptığımız işlerimizin sonunda filmleri kullanıcılara önermek için herhangi bir çalışma gerçekleştirmemiştik. Şimdi kullanıcılarımıza eğitmiş olduğumuz verilere göre önerileri sunacağımız çalışmayı gerçekleştireceğiz.
Şimdi öncelikle kullanıcılarımıza film önerileri sunmak için en iyi üç filmi alacağız. Bunun için recommendForAllUsers() yöntemine sahibiz ve bu fonksiyonumuzu en iyi üç film için kullanacağız. Daha sonrasında ise almış olduğumuz bu verinin veri tiplerini gözlemleyeceğiz.
userRecsAll = model.recommendForAllUsers(3)
userRecsAll

Gördüğümüz gibi kullanıcı kimliği integer tipine sahip bununla birlikte en iyi üç film ise array bir yapı içerisinde bizlere geldi. Bu array içerisinde ise film kimliği ve almış olduğu puan yani rating verisini içermektedir.
Şimdi userRecsAll içerisine almış olduğumuz data framemizi kontrol edelim.
userRecsAll.toPandas().head()
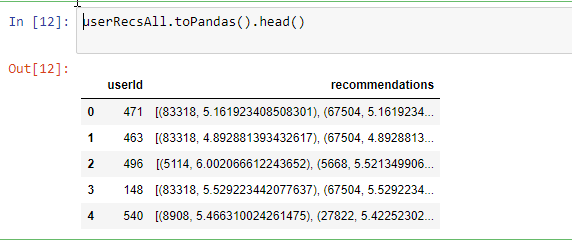
Data frame içerisine almış olduğumuz userRecsAll içeriğini toPandas().head() methodu ile çağırdığımızda her bir kullanıcımız için en iyi üç film önerisinin bulunduğunu gözlemleyebildiğimizi ekran görüntüsünde de görüldüğü gibi gözlemleyebildik.
ALS modelinin bizlere sağladığı bir diğer avantajda tersine bilgiyi de alabilmemizdir. Yani bu ne demek belirli bir filmi beğenme olasılığı en yüksek olan kullanıcıları da getirebiliriz. Daha önceki adımda bütün kullanıcılar için en iyi filmleri getirmiştik ve model.recommendForAllUsers metodunu kullanmıştık. Şimdi ise model.recommendForAllItems() metodunu kullanacağız.
movieRecsAll = model.recommendForAllItems(3)
movieRecsAll.toPandas().head()
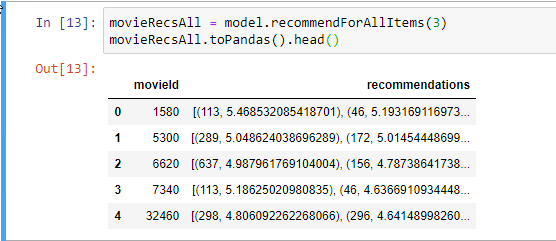
Görüldüğü gibi belirli bir filmi beğenme olasılığı en yüksek olan kullanıcılarımızı da alabildik. Bu fonksiyonumuz her bir film için sadece üç kullanıcıyı bizlere döndürür. Eğer daha fazla kullanıcının dönmesini istiyor isek o zaman model.recommendForAllItems(3) fonksiyonunda yer alan üç değerini artırabiliriz.
Bizler öneri modelimizi geliştirirken ya da uygularken veri setimiz içerisinde bulunan bütün kullanıcılarımız için önerilere ihtiyaç duymayız. Yalnızca hedef kullanıcı grupları ya da tek bir kullanıcı için önerilere ihtiyaç duyarız. Özetle yalnızca belirli ve hedef kullanıcı grupları için öneriler alırız. Bunun içinde ilgilendiğimiz kullanıcı ya da kullanıcı grupları için bir data frame oluştururuz.
from pyspark.sql.types import IntegerType
usersList = [148, 463, 267]
usersDF = spark.createDataFrame(usersList, IntegerType()).toDF(‘userId’)
usersDF.take(3)
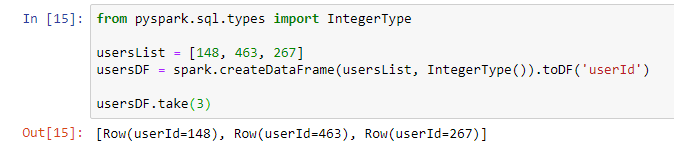
Örnek olarak 148,463,267 kimliğine sahip kullanıcı listesini bir data frame içerisine aldım ve almış olduğum kullanıcı kimliklerini oluşturduğum başka bir data frame içerisine doldurdum.
Burada amacımız aslında bu üç kullanıcı için en iyi film önerilerini almaktır.
userRecs = model.recommendForUserSubset(usersDF, 5)
userRecs.toPandas()
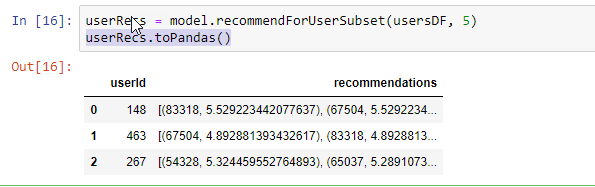
Artık hedeflediğimiz kullanıcılarımız mevcut. Hedeflediğimiz kullanıcı grubu için ise recommendForUserSubset() metodunu çağıracağız. Bu metot bize hedef kullanıcılar için en iyi beş film önerisini sunacaktır.
Pekala bizler kullanıcı gruplarına göre artık önerilere sahibiz ve bu önerilerde UserRecs data frame içerisinde yer almakta olduğunu biliyoruz. Bizler bu gruplar içerisinde spesifik kullanıcıları almak isteriz, işte bu noktada bir filtre uygulayacağız.
userMoviesList = userRecs.filter(userRecs.userId == 148).select(‘recommendations’)
userMoviesList.collect()

Gördüğümüz gibi spesifik bir kullanıcımız olan ve 148 kullanıcı kimliğine sahip kullanıcımıza film önerilerimizi sunabildik. Şimdi bu kullanıcımız için önerilmiş filmleri alalım. Bunun için bir önceki adımda gerçekleştirilmiş ve 148 kullanıcı kimliğine sahip kişi için önerilen beş adet filmi alacağız.
moviesList = userMoviesList.collect()[0].recommendations
moviesList
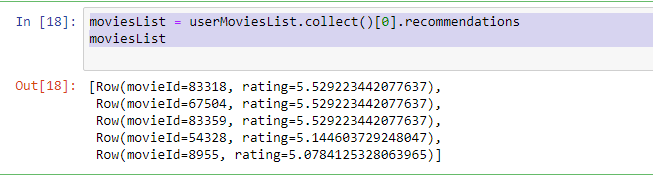
Bunun için userMoviesList.collect()[0].recommendations metodu ile bilgileri alabildik. Gördüğümüz gibi elimizde ki veri bir array ve bu array aslında structure yapıda. Bu arrayi data frame içerisine kolon isimleri ile birlikte başka bir data frame içerisine yazdıracağız. Bunun için ise spark.createDataFrame(dataframe) metodunu kullanacağız.
moviesDF = spark.createDataFrame(moviesList)
moviesDF.toPandas()
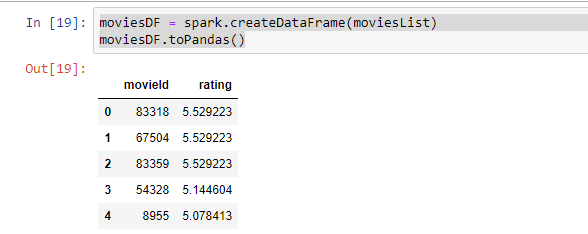
Gördüğümüz gibi movieList içerisinde array olarak bulunan datamız yeni bir data frame içerisinde daha anlamlı bir tablo haline geldi. Burada bulunan movieID isimli kolon ile elimizde bulunan veri setindeki movieId kolonlarını birleştirerek artık film isimlerini de alabilecek bir veriye de sahip olmuş olduk.
Şimdi artık elimizdeki film veri setini okutacağız ve kolonları birleştirerek kullanıcımıza önerdiğimiz film isimlerini de artık öneri olarak sunabilir duruma gelebilecek durumdayız. Elimizdeki veri setini aşağıda şekilde yeniden spark ortamına vereceğiz ve yeni bir data frame oluşturacağız. Bunun için yine spark.read fonksiyonunu kullanarak veriyi spark ortamında yeni bir data frame içerisine alacağız.
movieData = spark.read.csv(‘C://oneri/movies.csv’,
header=True,
ignoreLeadingWhiteSpace= True)
movieData.toPandas().head()
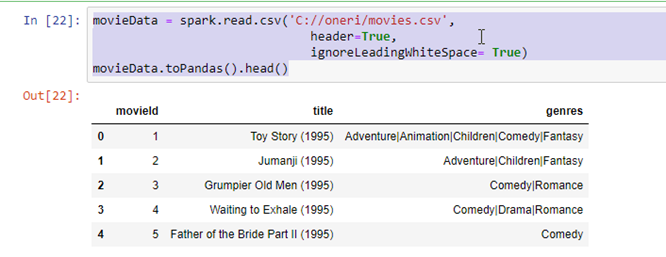
Evet artık bu data frame içerisinde filmlerimizin ve film türlerinin olduğu bir veri setimiz daha var. Bir önceki adımda kullanıcımıza önerdiğimiz film kimlik numaraları ile movieData içerisinde bulunan film kullanıcı kimliklerini birleştirerek film kimlik numarası yerine film ismini kullanıcılarımıza önermeliyiz ki anlamlı bir öneride bulunabilelim.
recommendedMovies = movieData.join(moviesDF, on=[‘movieId’]).orderBy(‘rating’, ascending=False).select(‘title’, ‘genres’, ‘rating’)
recommendedMovies.toPandas()
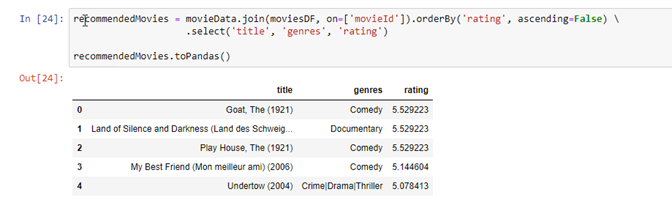
Evet movieData veri setimizi bir data frame içerisinde bulunan movieID ile moviesDF içerisinde olan movieID isimli kolonlar aynı olduğunu biliyoruz ve bundan dolayı bir join işlemini gerçekleştirdik. Yani farklı data frame’lerin birleştirilmesi işlemini gerçekleştirdik. Fakat birleşme sonrasın ihtiyacımız olan kolonları da belirttik. MovieData data frame içerisinde bulunan title,genres ve MoviesDF data frame içerisinde yer alan rating kolonlarının seçimini yaparak öneride bulunduğumuz filmleri isimleri ve kategorileri ile getirmiş olduk.
Buraya kadar olan her şey tamamlandı. Fakat bu noktada eksik olan kısım öneri sistemimizde spesifik kullanıcılarımız için önerilerde bulunmamız gereken alana geldik . Bunun için yukarıda gerçekleştirdiğimiz işlemleri aslında bir fonksiyon haline getireceğiz ve bundan sonra tanımlanmış spesifik kullanıcılarımız için aynı kodları yazmak yerine aşağıda belirtilen fonksiyonu kullanıcı önerilerde bulunacağız. Bunun için aşağıdaki şekilde bir fonksiyon oluşturucağız.
from pyspark.sql.types import IntegerType
def getRecommendationsForUser(userId, numRecs):
usersDF = spark. createDataFrame([userId], IntegerType()). toDF(‘userId’)
userRecs = model.recommendForUserSubset(usersDF, numRecs)
moviesList = userRecs.collect()[0].recommendations
moviesDF = spark.createDataFrame(moviesList)
recommendedMovies = movieData.join(moviesDF, on=[‘movieId’]) .orderBy(‘rating’, ascending=False) .select(‘title’, ‘genres’, ‘rating’)
return recommendedMovies
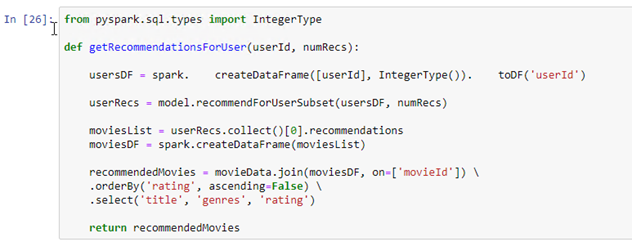
Oluşturmuş olduğumuz fonksiyon daha önce tek tek gerçekleştirmiş olduğumu adımları tek bir noktada toplamaktadır. Öncelikle kullanıcı bilgisi için yeni data frame oluşturmaktayız. Biz bu işlemi için bütün kullanıcılar için önerileri oluşturmak yerine hedef kullanıcı ya da kullanıcı grupları için bu önerileri sunarız diye belirtmiştik. İşte burada hedef kullanıcı bilgisi için bir kullanıcı data frame oluşturduk. Daha sonra yine ALS algoritmamızın yeteneği olan ve recommendForUserSubset metodunu kullandık ve spesifik kullanıcımız için en yüksek puanlamayı yapacağı film tahminlerini seçecek ve seçmiş olduğu bu filmleri bir array içerisine alacağız. Bu array içerisinde bulunan veri yine yeni bir data frame içerisine alacak fakat daha structure bir yapıda tutacağız. Bu andan sonra yine movieData veri setimiz içerisinde yer alan film kimliği ile joinleyecek ve kullanıcımıza önerimizi film adı ile birlikte gerçekleştirecek duruma geleceğiz.
Peki bu işlemler sonrasında bir hedef kullanıcı kimliği ve bu kullanıcı kimliğine sahip kişi için 10 adet film önerisini çalıştıralım.
recommendationsForUser = getRecommendationsForUser(219, 10)
recommendationsForUser.toPandas()
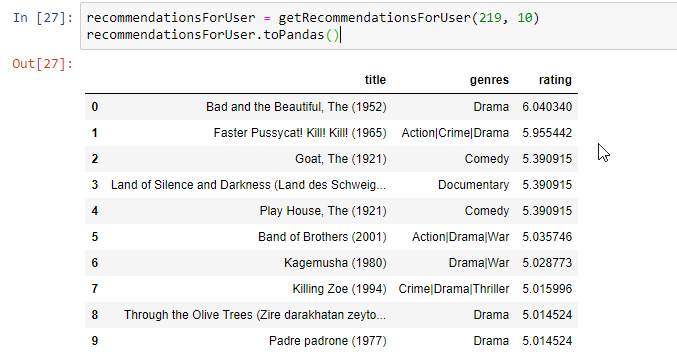
Gördüğümüz gibi film isimlerini ve kategorilerini çağırdık. Tahminleme yaparken vereceği derecelendirmeyi tahmin ettiğimiz gibi bu kullanıcı kimliğine sahip olan kişinin aslında dram ve komedi film kategorilerini tercih ettiğini de gözlemlemiş oldu. Açık derecelendirme ile yapılan ve ALS algoritmasını kullandığımız öneri sistemimizin de %95 oranında doğruluğu yakaladığını görmüş ve değerlendirmiştik.
Böylelikle açık derecelendirme bulunan bir veri seti üzerinde öneri uygulamasını gerçekleştirmiş olduk.